ASRT:一个基于深度学习的中文语音识别系统
摘要
ASRT 是一套基于深度学习的中文语音识别系统,全称为 Auto Speech Recognition Tool,由 AI 柠檬博主开发并在 GitHub 上开源(GPL v3.0 协议)。ASRT 可以用来帮您快速上手语音识别技术,简单操作即可实现模型训练、评估、预测和服务部署,支持使用客户端 SDK 二次开发,支持开箱即用,可以直接下载并运行部署已打包的发布版 API 服务软件,或使用 Docker 一键部署。
本项目声学模型通过采用深度卷积神经网络(DCNN)和连接时序分类(CTC)方法,使用大量中文语音数据集进行训练,将声音转录为中文拼音,并通过语言模型,将拼音序列转换为中文文本,算法模型在测试集上已经获得了 80% 的正确率。
基于该模型,在 Windows 平台和 Web 平台上实现了一个基于 ASRT 的语音识别应用 Demo 软件,取得了较好应用效果。这个应用软件包含 Windows 10 UWP 商店应用和 Windows 版。Net 平台桌面应用和 JavaWeb 网站 Demo,也一起开源在 GitHub 上了。
特征提取
将普通的 wav 语音信号通过分帧加窗等操作转换为神经网络需要的二维频谱图像信号,即语谱图。

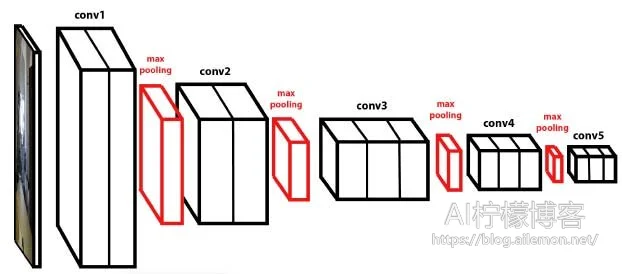
模型
声学模型
DCNN + CTC
用于实现将声学信号转换为拼音标签序列
基于 Keras 和 TensorFlow 框架,使用这种参考了 VGG 的深层的卷积神经网络作为网络模型,并训练。
CTC 解码
在语音识别系统的声学模型的输出中,往往包含了大量连续重复的符号,因此,我们需要将连续相同的符合合并为同一个符号,然后再去除静音分隔标记符,得到最终实际的语音拼音符号序列。

语言模型
基于概率图的马尔可夫模型,用于实现将拼音标签序列转换为最终对应的中文文本,就是识别出来的文字。
拼音转文本的本质被建模为一条隐含马尔可夫链,这种模型有着很高的准确率。
基于 HTTP 协议的 API 接口
本项目使用了基于 http 协议的 Python 包实现了 RESTFul 模式的 API 接口服务。通过将声学模型和语言模型连接起来,调用该服务接口,可以直接实现语音识别。
客户端和 SDK
本项目的客户端分为 4 种,其中 2 种为 Windows 客户端,一个是 UWP 客户端,另一个是 WPF 客户端,源码均需要使用 VS2017/2019 来开发和编译,使用 C#和 XAML 编写。项目包含有界面逻辑和录音模块、语音识别 API 调用模块,并包含对 wav 文件的 raw 格式进行的解析。
另外两种为 python 版客户端(sdk)和 java+web 端。
客户端通过自动控制录音的中断时间、两个录音模块连续交替录音,以及异步发送请求操作,最终按照先后顺序将返回结果显示在界面的文本框中,实现了长时间连续语音识别的功能。
更多信息
更多关于 ASRT 开源语音识别项目请访问:
ASRT 项目 GitHub 仓库 或 ASRT 项目 Gitee 仓库
ASRT 语音识别项目文档 (很重要,一定要看哦)
实用效果体验 Demo
西安电子科技大学 · 西安市大数据与视觉智能重点实验室